So we had 6 NAS systems with a total of 24 WD60-EFAX 6TB SMR drives running BTRFS storate pools. Due to the horrible performance of the SMR drives we opened a ticket with WD and got all of the drives replaced with WD60-EFRX drives.
Allthough we had BTRFS snapshots replicated to our backup layer we still wanted to retain the local BTRFS snapshots. So we simply replaced the EFAX drives with EFRX drives one-by-one mainting the integrity of the storage pool. We ran the SMART check on each new disk and each disk got approved without errors. This was a process spanning several weeks as not to create down-times to the customers. We were lucky that the effected boxes were exclusively deployed for AB4B so not customer suffered from the poor performance.
This morning I had the 3rd unreponsive DS1522+ in 3 weeks were one of the replacement EFRX crashed. The NAS became so unresponsive that 2FA blocked the login and the system became bricked. Not even SMB was working.
I regained access:
- remove all 4 EFRX drives,
- insert a new 5th drive as tempory drive.
- Install DSM (to chekc if NAS or disk are faulty)
- Turn off System
- Reinsert the 4 EFRX drives (the complete storage pool, including the faulty disk)
- Start Synology Assistant → search for NAS → Migrteable NAS found
- reinstall DSM with Mode2 reset (maintains data but not settings)
- remove the 5th disk
Now the NAS is back online with the storage pool of the old NAS in critical condition because the crashed HDD was not mountet to the storage pool. But it was resposibe again and all data seem to be there.
Checking the health information of the crashed disk I get absolutely no error indication.
I have exactly the same behaviour on 3 different NAS systems (DS1520+; DS1522+, DS1522+) with brand new WD60-EFRX disk coming from different production batches of WD
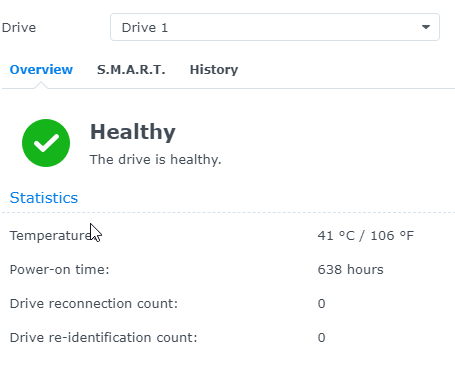
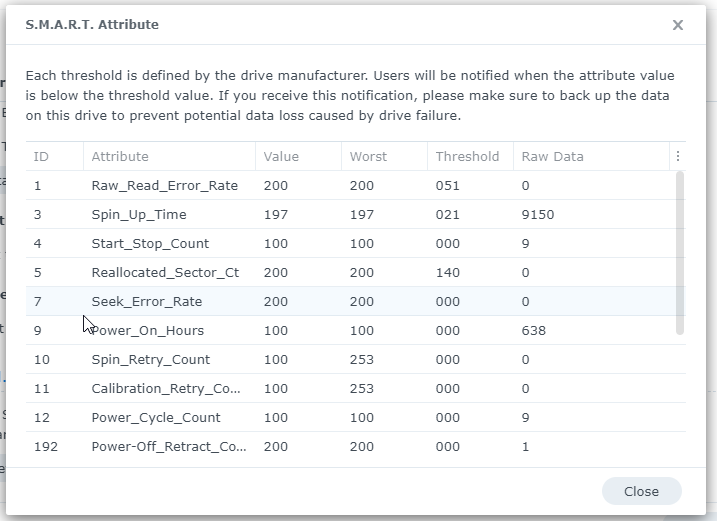
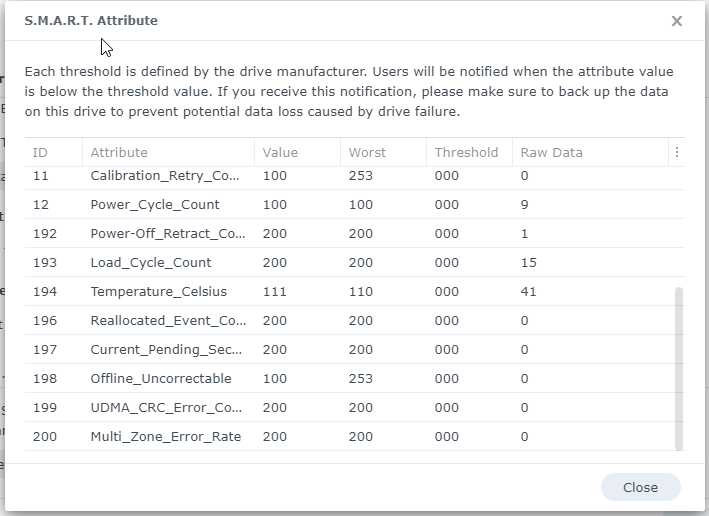
What am I missing here? After rebuilding the storge pools on the other NAS I got some corruption warnungs but data scrubbing says it has repaired the issues.
I know the precise moment the NAS crashed and I have replicated snapshots (now flagged “blocked” againts deletion through space reclamation) in the local network. So if the current pool should turnes out to be corrupt I can always do a fail-over and merge with a current snapshot. So the data corruption is not my biggest issue.
I am more concerend as to why these systems crashed, if they will contirnue to crash, if there might be bad luggage from the SMR storage pool,…
On the long run I will likely replace all WD disk with disks from other vendors, most likely with EXOS 16TB (over 50pcs installed with no problems so far)
But none of the 3 failing discs has more than 1000hrs
I will not open an ticket with Synology as in the past this turned out to be a waist of time.
I appreciate your opinions